Discord sucks! ...so I made my own
How I built Eko - THE discord alternative for terminal nerds
Discord sucks
I have been disatisfied with discord for a few years by now, the main reasons that most people will agree with me, are it’s slow, sluggish, bloated, and that it gets worse over time.
- Reduced upload size from 50mb to 10mb
- Ugly UI revamps
- Literally ships with an entire browser (chromium due to electron)
But there are a few more personal reasons for me.
Ignoring the fact that I am in 100 servers and literally can’t join any more, as someone who spends most of his day in the terminal, writing code with NVIM (btw), I really missed vim motions in discord, they are great and I’d probably talk about them in the future.
Searching for alternatives
Vim motions are so ubiquitous they are practically everywhere, not just coding editors like Zed and vsc*de but also note taking apps like Obsidian, and heck, even google docs have an extension for them.
Surely an app as popular as Discord will have them right? well after some searching I found Cordless , a discord client in the terminal, great!
Reading the readme, I immediately got dissapointed, the project has been shutdown. The reason was due to a high risk of Discord banning users for ToS violation, so I couldn’t even make my own client!
The idea
So I thought to myself, if Discord doesn’t let me make a client, I’ll write my own Discord, complete with a backend, frontend and most importantly, vim motions!
Great, now that I have the idea, what languages do I use for the backend and the frontend?
I heard that golang is a really good language for the backend, due to it’s concurrency model making it easy to handle a ton of connections simultaneously.
And what about the frontend? I’d need to find some library to help me make a TUI (terminal UI), After some searching, I found bubbletea from charm , a golang library for creating TUIs, perfect.
This has the added benefit of the backend and frontend being able to share types as they are written in the same language.
The implementation
The frontend
Bubbletea uses the Elm architecture to create a UI, it is made out of 3 components:
- The model - the state of the UI, it can contain UI elements, buttons, styles, and even other models
- The view - a function that takes a model and returns the UI, in the case of a TUI, it just returns a string
- The update - a function that takes the model and a message, and computes a new model based on that message
The way it works, is a new message comes, for example a user resized the window, this message gets propagated to the model via the update method, which produces a new model, then the view method takes the new model and renders the new state to the UI.
The concept itself is really great, although Bubbletea, partly due to golang had to make a few tradeoffs which made me like it less.
First, golang doesn’t have the concept of “const”, so the view must take a copy of the model, FOR EVERY RE-RENDER, this is extremely inefficient, especially that most models can take thousands of bytes if not more, and that the copy is being pased on the stack.
This doesn’t only happen on view, this also happens in the update function, every update, the model also gets copied and passed on the stack, then the function modifies the stack version and returns a new version of it that is then also, gets copied on the stack.
This is due to the Elm architecture originating from Elm, a functional programming language, in such languages mutating is discouraged, and everything gets copied.
The backend
The server itself is fairly boring, it has a loop that accepts new TCP/TLS connections, and it spawns a new goroutine (“Green thread”) to handle the client requests.
So instead, let’s talk about how IDs are handled!
My first idea was to use a UUID (universally unique identifier), but it takes 128 bits, that seems way too much, 32 bits already allow for 4 billion permutations, but just in case (see IPv4 lol), 64 bits should be plenty, that’s 18 quintillion!
For the format, is it fine to just randomly generate them? 18 quintillion is alot, but the chance of collissions is not as low as I’d like it to be, I wonder what Discord uses for their IDs…
Snowflake IDs
Discord uses snowflake IDs, originally invented by Twitter, they are 64-bit with a special format that guranteed uniqueness across multiple machines and data centers, here’s how they work:
0 1 2 3 4 5 6 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+|s| Milliseconds since Epoch | Node ID | Mac ID | Incremented |+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+- s - The sign bit when storing the ID as an int64, unused (always 0)
- Milliseconds since Epoch - The number of milliseconds since some date, in Twitter’s case this is 2010, for Discord it’s 2015, and for Eko it’s 2025
- Node ID - A unique identifier for the data center or cluster, in case of Eko this is always just 1 as I run eko on a single VPS server
- Mac ID - The specific machine ID within a cluster, in Eko this is combined with the NodeID into a single 10-bit field, with a value of 1
- Incremented - If 2 IDs are generated in the same millisecond, this is incremented, up to 4095 times, allowing a single machine to generate 4 million IDs per second (1000 * 4096)
The snowflake ID also has the nice benefits of embedding a timestamp in it, this allows to save even more space by not needing to store a separate unix timestamp for creation dates, the creation date of a user is when their ID was first generated.
If you are interested in knowing when your discord account was created, there are websites that allow you to check this.
Because everything in Eko uses snowflake IDs (users, networks, frequencies, messages) this trivially allows us to view the timestamp, the client just shifts 22 bits to get the milliseconds, adds the hardcoded Epoch, formats the unix timestamp, and now you got timestamps of messages.
The protocol
Ok, so we have the backend, we have the frontend, but how will they communicate over the network?
The first thought that came to mind, was to use whatever Discord uses, which is HTTPS and websockets, but this felt wrong, using such a bloated protocol just for sending a few text messages.
I decided it’d be better to design my own protocol from scratch, that’d be efficient and small. After a while of planning, I came up with this packet format:
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+| Version |En.| Type | Payload Length |+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+| Payload... Payload Length bytes ... |+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+- Version (8 bits) - the most important thing when designing a protocol is to have a version field, so that when you inevitably introduce breaking changes, the server and client will notice a mismatch and know how to deal with it
- Encoding (2 bits) - Indicates the format of the payload, more on that later
- Type (6 bits) - The type of the payload, what kind of message it is
- Payload Length (16 bits) - How long is the payload, 16 bits gives us a maximum payload size of 65,536 bytes
- Payload (0-65k bytes) - The actual body of the message, formatted per the encoding
I was thinking about how to encode the payload in an efficient format, JSON was just too verbose for this, after taking a look at protobufs, cap’n proto and MsgPack, I chose MsgPack, mostly because of it’s ease of use while being almost as fast as the other 2.
But I still wanted to support JSON, so I introduced a 2-bit encoding into my packet, the idea is the packet sender specifies 0 for JSON, 1 for MsgPack, and the other 2 are reserved. That way the server and client can communicate with MsgPack, but if a developer writes their own client that uses JSON, the server can handle that just as fine.
Another thing to mention is how the type thing is used as a “tagged union”, it specifies the structure of the payload, unlike a tagged union though, it doesn’t need to store the size of the largest packet, that’s what the payload length field is for.
The release
After months of work, I am happy to present…
Eko - a terminal-native discord alternative for terminal enthusiasts!
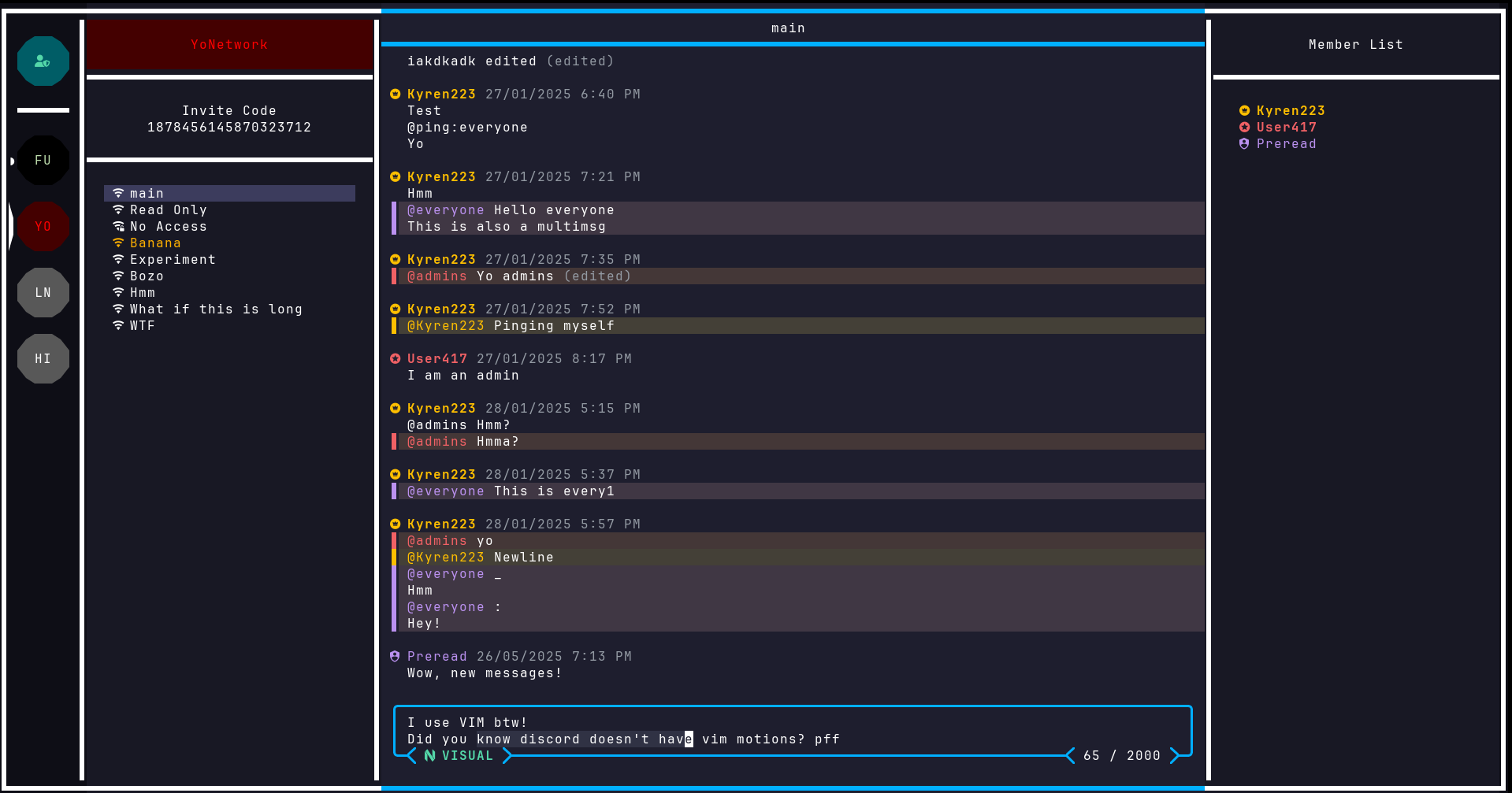
For more information head over to the README , or install it now with
curl -sS https://eko.kyren.codes/install.sh | shHope to see you there!
As always if you have questions or want to chat, feel free to contact me on discord at Kyren223 or email me at contact@kyren.codes .
You can also add me on Eko, here’s my ID: 2102554263552